
谷歌已经全面拥抱双子座时代。



在 I/O 大会结束时,谷歌在山景城 Shoreline Amphitheatre 举行的年度开发者大会上,谷歌首席执行官桑达尔·皮查伊 (Sundar Pichai) 透露,该公司已经提到“AI”121 次。从本质上讲,这就是谷歌两小时主题演讲的核心——将人工智能融入全球超过 20 亿人使用的每一个谷歌应用程序和服务中。以下是谷歌在此次活动中宣布的所有主要更新。
Gemini 1.5 Flash 和 Gemini 1.5 Pro 的更新

谷歌宣布推出名为 Gemini 1.5 Flash 的全新人工智能模型,据称该模型针对速度和效率进行了优化。 Flash 介于 Gemini 1.5 Pro 和 Gemini 1.5 Nano 之间,后者是该公司在设备上本地运行的最小型号。谷歌表示,它创建 Flash 是因为开发人员想要一种比 Gemini Pro 更轻、更便宜的模型来构建人工智能驱动的应用程序和服务,同时保留一些东西,例如一百万个令牌的长上下文窗口,这些东西使 Gemini Pro 与竞争模型区分开来。今年晚些时候,谷歌将把 Gemini 的上下文窗口增加一倍,达到 200 万个代币,这意味着它将能够同时处理 2 小时的视频、22 小时的音频、超过 60,000 行代码或超过 140 万个单词。
阿斯特拉计划
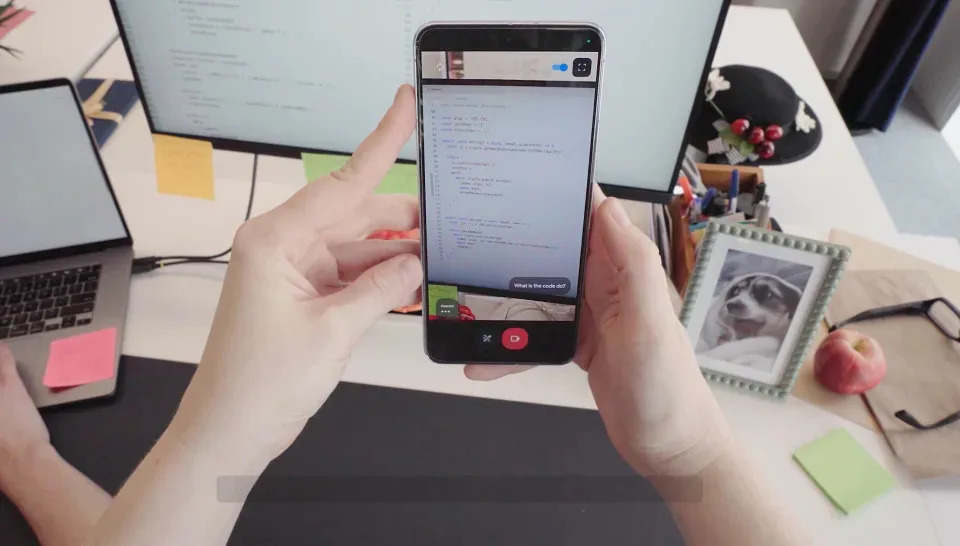
谷歌展示了Project Astra,这是由人工智能驱动的通用助手的早期版本,谷歌 DeepMind 首席执行官 Demis Hassabis 表示,这是谷歌版本的人工智能代理,“可以在日常生活中提供帮助”。
在谷歌称是一次拍摄的视频中,一名 Astra 用户在谷歌伦敦办公室周围走动,举起手机,将摄像头对准各种物体——扬声器、白板上的一些代码、窗外——然后与应用程序就其外观进行自然对话。在视频中最令人印象深刻的时刻之一,它正确地告诉用户她之前把眼镜放在哪里,而用户甚至没有拿起眼镜。
视频结尾有一个转折——当用户找到并戴上丢失的眼镜时,我们了解到他们有一个机载摄像系统,并且能够使用 Project Astra 与用户无缝地进行对话,这或许表明谷歌可能正在努力Meta 的雷朋智能眼镜的竞争对手。
询问 Google 照片
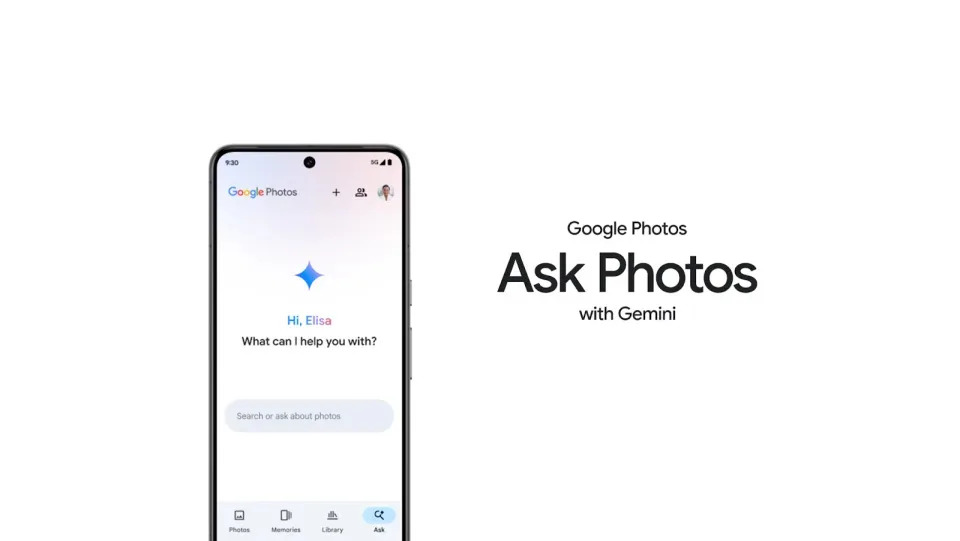
在搜索特定图像或视频时,谷歌照片已经很智能,但通过人工智能,谷歌正在将事情提升到一个新的水平。如果您是美国的 Google One 订阅者,当该功能在未来几个月推出时,您将能够向 Google Photos 提出一个复杂的问题,例如“向我展示我访问过的每个国家公园的最佳照片”。谷歌照片将使用GPS信息以及它自己的“最佳”判断来为您提供选项。您还可以要求谷歌照片生成标题以将照片发布到社交媒体。
Veo 和 Imagen 3

谷歌新的人工智能媒体创建引擎被称为 Veo 和 Imagen 3。Veo 是谷歌对 OpenAI 的 Sora 的回应。谷歌表示,它可以制作持续时间“超过一分钟”的“高质量”1080p 视频,并且可以理解延时拍摄等电影概念。
与此同时,Imagen 3 是一个文本到图像生成器,谷歌声称它比之前的版本 Imagen 2 能更好地处理文本。其结果是该公司最高质量的“文本到图像”模型,具有“令人难以置信的细节水平”。逼真、逼真的图像”和更少的伪影——本质上是与 OpenAI 的 DALLE-3 进行竞争。
Google 搜索的重大更新

谷歌正在对搜索的基本运作方式进行重大改变。今天宣布的大多数更新都包括能够提出非常复杂的问题(“找到波士顿最好的瑜伽或普拉提工作室,并显示他们的介绍优惠和从灯塔山步行时间的详细信息。”)以及使用搜索来计划膳食和假期除非您选择加入搜索实验室,否则无法使用该实验室,这是该公司的平台,可让人们尝试实验性功能。
但谷歌称之为“人工智能概览”的一项重要新功能,该公司已经测试了一年,终于向数百万人推出。谷歌搜索现在将默认在结果之上显示人工智能生成的答案,该公司表示,到今年年底,它将为全球超过 10 亿用户提供该功能。
Android 上的双子座
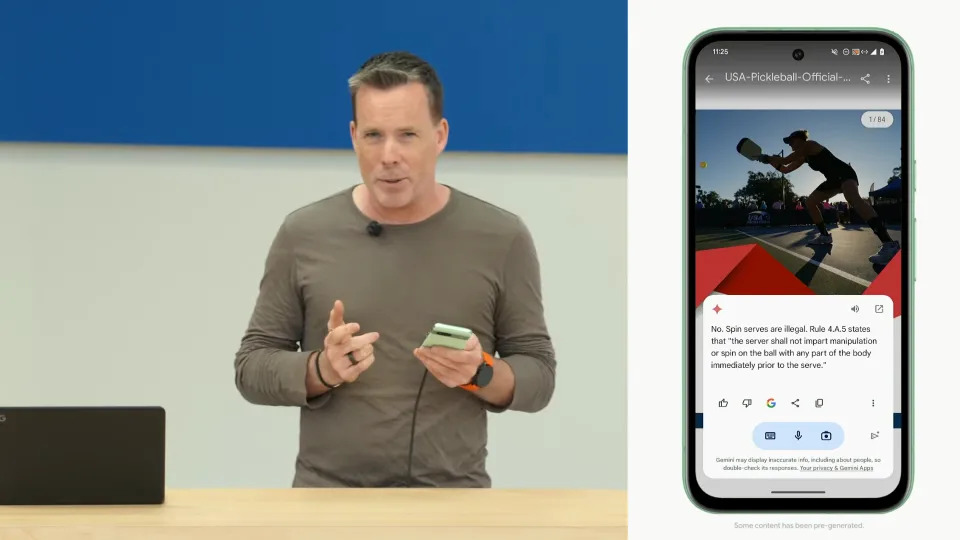
谷歌正在将 Gemini直接集成到 Android 中。当 Android 15 今年晚些时候发布时,Gemini 将意识到您正在运行的应用程序、图像或视频,您将能够将其作为覆盖层拉出并询问特定于上下文的问题。已经做到这一点的 Google Assistant 会怎样呢?谁知道!谷歌在今天的主题演讲中根本没有提及这个问题。
还有很多其他更新。谷歌表示,它将在人工智能生成的视频和文本中添加数字水印,使 Gemini 可在 Gmail 和 Docs 的侧面板中访问,为Workspace 中的虚拟人工智能队友提供支持,监听电话并检测您是否在真实情况下被骗。时间,还有更多。
- 谷歌全新Gemini 1.5 Flash AI模型比Gemini Pro更轻、更易用新模型将降低开发人员使用谷歌模型构建人工智能应用程序的成本。

谷歌
周二,谷歌在公司开发者年度大会 I/O 上宣布了其Gemini 系列人工智能模型的更新。该公司正在推出一款名为 Gemini 1.5 Flash 的新型号,据称该型号针对速度和效率进行了优化。
“[Gemini] 1.5 Flash 擅长摘要、聊天应用程序、图像和视频字幕、从长文档和表格中提取数据等,”Google DeepMind 首席执行官 Demis Hassabis 在一篇博客文章中写道。 Hassabis 补充说,谷歌创建 Gemini 1.5 Flash 是因为开发人员需要一个比谷歌2 月份宣布的Pro 版本更轻、更便宜的模型。 Gemini 1.5 Pro 比该公司去年年底发布的原始 Gemini 型号更高效、更强大。
Gemini 1.5 Flash 介于 Gemini 1.5 Pro 和 Gemini 1.5 Nano 之间,后者是 Google 在设备上本地运行的最小型号。尽管重量比 Gemini Pro 轻,但它的功能同样强大。谷歌表示,这是通过一个名为“蒸馏”的过程实现的,将 Gemini 1.5 Pro 中最重要的知识和技能转移到较小的模型上。这意味着 Gemini 1.5 Flash 将获得与 Pro 相同的多模式功能,以及其长上下文窗口(AI 模型一次可以摄取的数据量)一百万个代币。据 Google 称,这意味着 Gemini 1.5 Flash 将能够同时分析 1,500 页的文档或超过 30,000 行的代码库。
Gemini 1.5 Flash(或任何这些型号)并不是真正适合消费者的。相反,对于开发人员来说,这是一种更快、更便宜的方式,可以使用谷歌设计的技术构建自己的人工智能产品和服务。
除了推出Gemini 1.5 Flash之外,谷歌还对Gemini 1.5 Pro进行了升级。该公司表示,它“增强”了该模型编写代码、推理以及解析音频和图像的能力。但最大的更新尚未到来——谷歌宣布今年晚些时候将模型的现有上下文窗口增加一倍,达到 200 万个代币。这将使其能够同时处理 2 小时的视频、22 小时的音频、超过 60,000 行代码或超过 140 万个单词。
Gemini 1.5 Flash 和 Pro 现已在 Google 的 AI Studio 和 Vertex AI 中提供公开预览版。该公司今天还宣布了 Gemma 开放模型的新版本,称为 Gemma 2。但是,除非您是开发人员或喜欢构建 AI 应用程序和服务的人,否则这些更新并不真正适合普通消费者。
文章来源于互联网:Google I/O 2024 上宣布的所有内容包括 Gemini AI、Project Astra、Android 15 等
相关推荐
-
谷歌Pixel 9系列曝光:本地AI功能再升级,文生图、智能问答等功能一应俱全
近日,业界知名消息源AssembleDebug深入剖析谷歌AI Core等应用程序的代码,揭示了谷歌即将发布的Pixel 9系列手机将搭载一系列前沿的本地AI功能。这些功能包括文字…
-
三星手机即将迎来Galaxy AI功能的大型软件更新
如果您在过去一年左右内购买了三星手机,那么请准备好迎接即将到来的一次重大软件更新。在2月21日,三星确认,一些较旧的智能手机将在“三月底”作为One UI 6.1更新的一部分获得G…
-
谷歌官宣“魔法橡皮擦”等 AI 修图功能下月下放至所有用户:每月限免 10 次
4 月 11 日消息,昨天IT之家报道了谷歌第一方“相册 App”内的多种 AI 编辑功能有望告别 Google One 会员独享的消息,现在这则消息得到了谷歌官方的确认。 根据谷…
-
自定义 GPT 等 GPT-4o 新功能现已向 ChatGPT 全体用户免费开放
5 月 30 日消息,ChatGPT 免费用户现已能够尝试自定义 GPT 模型、分析图表等其他 GPT-4o 新功能。当然,OpenAI 在推出 GPT-4o 时就承诺它将免费向所…
-
苹果研究人员揭示新的人工智能系统,可击败 GPT-4
苹果的研究人员开发了一种名为 ReALM(Reference Resolution as Language Modeling)的人工智能系统,旨在根本改善语音助手理解和响应命令的方…
-
OpenAI Sora发布:引领AI视频时代的新篇章
旧金山巨头OpenAI近日推出Sora模型,引领AI视频时代新潮流。这一创新技术能够将文字迅速转化为超现实视频,赋予创作者无限想象。 Sora目前仅供专家和创意人士使用,旨在收集反…
-
如何在手机上获取Sora AI
想要直接从您的移动设备上访问Sora AI的强大功能吗?在本指南中,我们将向您展示如何在手机上获取Sora AI,让您可以随时随地利用人工智能技术创建令人惊叹的视觉和视频。按照以下…
-
如何在任何iPhone或Android手机上尝试三星的Galaxy AI功能
三星刚刚在一月份发布了全新的Galaxy S24系列,其中最大的卖点之一就是Galaxy AI。无论你是喜欢还是讨厌,移动AI的时代已经到来,而Galaxy AI是三星提供的一套A…
-
手机AI功能的革新:如何让智能手机更智能
每年都如期而至,世界上一些最大的公司都会发布新款手机,希望你能为此花费数百美元。 但是,近年来,它们越来越倾向于一种新的角度来吸引你考虑升级:人工智能。 AI功能:现实生活中的得力…
-
谷歌:手机运行人工智能模型将占用大量内存
3 月 31 日消息,谷歌在 3 月初发布了一个奇怪的声明,称旗下两款新手机 Pixel 8 和 Pixel 8 Pro 中,只有 Pixel 8 Pro 能够运行其最新的人工智能…